The new
Android 1.5 Early Look SDK is out since a few weeks. The
"Android 1.5 highlights" page does not mention one highlight, which IMHO will become very important for all developers on the Android platform because it allows you to find memory leaks easily and analyze the memory usage of your Android applications.
I'm talking about the
hprof-conv tool that allows you to convert an Android/Dalvik heap dump into an .hprof heap dump. The tool does not preserve all the information, because Dalvik has some unique features such as cross-process data sharing, that are not available in a "standard" JVM. Still the .hprof file is a good starting point and can be read with the
Eclipse Memory Analyzer, which will interpret it like a normal file from a Sun 32 bit JVM. In the future it should also be not that difficult to read the Dalvik heap dump format directly and provide more information for memory analysis, such as which objects are shared and also maybe how much memory is used by native Objects (haven't checked that).
How to get a heap dumpFirst we must of course get a heap dump. I do not yet own an Android phone, also I plan to get on this year. If you want to donate one, please let me know. Donating lot's of money would also help ;)
I therefore created the heap dump using the emulator.
I created a new avd for the 1.5 preview:
android create avd -n test -t 2
emulator -avd test
Then you can logon to the emulated phone and make sure that the /data/misc directory is writable :
adb shell
chmod 777 /data/misc
exit
Heap dumps are actually created by sending the process a SIGUSR1 (-10) signal.
adb shell ps
check for the pid of your application
adb shell kill -10 pid
You can check with
adb shell logcat
whether it works. You should see something like:
I/dalvikvm( ): threadid=7: reacting to signal 10 I/dalvikvm( ): SIGUSR1 forcing GC and HPROF dump I/dalvikvm( ): hprof: dumping VM heap to "/data/misc/heap-dump-tm- pid.hprof-hptemp". I/dalvikvm( ): hprof: dumping heap strings to "/data/misc/heap-dump-tm124026 3144-pid.hprof". I/dalvikvm( ): hprof: heap dump completed, temp file removed D/dalvikvm( ): GC freed 1292 objects / 92440 bytes in 11 sec D/dalvikvm( ): GC freed 215 objects / 9400 bytes in 963msnow you can copy the heap dump from the (emulated) phone to the Desktop machine:
adb pull /data/misc/heap-dump-tm-pid.hprof address.hprof
Now the file you will get does not conform to the "standard" Sun .hprof format but is written in Dalvik's own format and you need to convert it:
hprof-conv heap-dump-tm-pid.hprof 4mat.hprof
Now you can use the Eclipse Memory analyzer to analyze the memory usage of your application.
Typical optimization opportunities
I described some typical issues already here in this blog for example a problem with Finalizers in Netbeans,
or finding "String duplicates" in Eclipse (my favourite memory analysis trick).
You might also take the time and check all my memory related posts.
Now I would like to present you a new typical memory usage issue that I just found when playing around with the new Android cupcake 1.5 prerelease.
YouShouldHaveDoneLazyInitialization
I did a heap dump of the android
gmail application and loaded it into the Eclipse Memory Analyzer.
In the histogram view I filtered the android classes:
The high number of Rect (Rectangle) objects looked suspicious to me. Also they retain not that much memory, I thought it would be interesting why such a high number of Rect instances was alive.
When checking the Rect objects I immediately saw that most of them seemed to be empty e.g. bottom=0 and left=0 and right=0 and top=0.
It seemed to me that this was the time to again use the most advanced feature in MAT. I'm talking about the OQL view, which allows you to execute SQL like queries against the objects in your heap dump.
I very rarely used this feature in the past because the standard queries are good enough almost all times and because writing your own command in Java is not that difficult.
Still here it would help me to find how many of the Rect instances where empty.
I entered
select * from android.graphics.Rect where bottom=0 and left=0 and right=0 and top=0 Which showed me that out of 1320 Rect instances 941 where "empty", which means that over 70% of the instances where "useless".
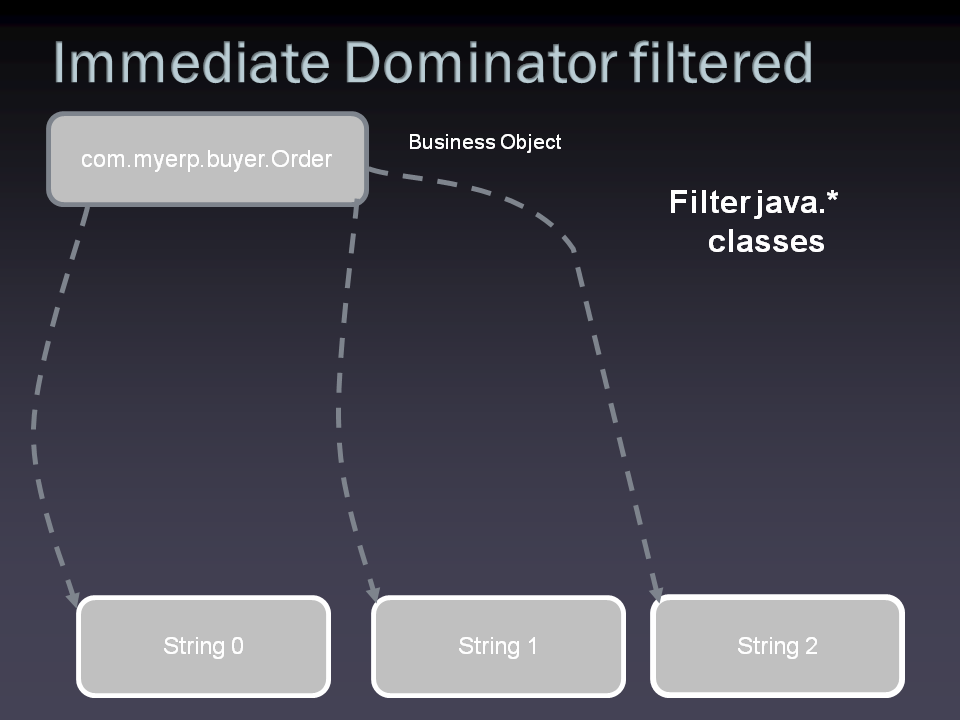
I used "immediate dominators" on the first 20 of those 941 instances, which showed me that those empty Rect instances were retained by several UI related
classes which are subclasses of
android.graphics.drawable.Drawable.
I checked the source and quickly found that Drawable
always instantiates a Rect using the default constructor:
public abstract class Drawable { private int[] mStateSet = StateSet.WILD_CARD; private int mLevel = 0; private int mChangingConfigurations = 0; private Rect mBounds = new Rect();Also this issue might not increase the memory usage of gmail that much it's still a fundamental/systematic problem, which IMHO should be fixed.
Even if we would tolerate the memory overhead, we are still left with the problem that the number of objects the garbage collector has to trace during Full GC is higher than needed, which at least potentially can lead to sluggish UI.
It's also a kind of fundamental problem because
all subclasses of Drawable inherit the problem.So instead of always using the default constructor it would
most likely better to use
lazy initalization and only initialize the field when it's first needed.
A
copy on write strategy could also be used by sharing an "empty" Rect instance in the beginning, which would be replaced by a new one as soon as the field is written ( haven't checked the code whether this can still be done).
Disclaimer:This is not a sign that Android is a poor platform. This is a kind of a problem that I've seen in the past more than once and I'm sure this kind of antipattern can be found in a lot of software out there.
UPDATE:
The issue has been fixed a few hours (or minutes?) after my post!
Check
https://review.source.android.com/Gerrit#patch,sidebyside,9684,2,graphics/java/android/graphics/drawable/Drawable.java
To see how simple the change was!
Just take the Eclipse Memory Analyzer and have a look at your application(s).
May the force be with you! ;)
Update 2:
In Android 2.3 (Gingerbread)
a new command is available to trigger the heap dump.
The kill command is not supported anymore.